
I previously wrote an article OpenCode Configuration Optimization Record, which addressed token consumption and context management issues. However, configuration optimization handles “how the model runs,” while “the quality of code when it’s half-written” is something configuration cannot manage. This article starts from my development process of the opencode-review plugin, discussing how opencode-review helps an agent review and improve its own code within a session, resulting in higher quality code entering the PR.
Problem: Who Guards Code Quality Within a Session?
When using OpenCode to write code, a typical workflow is: the agent completes coding within a session, then I review the diff and create a PR. But I discovered a recurring problem: code written by agents often enters PRs with “first draft” quality issues.
These issues include: missing error handling, security vulnerabilities, poorly performing queries, and missing tests. If the agent could perform a self-review within the session—before the code is committed to the PR—many problems wouldn’t exist at the PR stage.
This is different from code review at the CI stage. I’ve already implemented CI review through opencode-actions (I previously wrote an introductory article)—it happens after PR creation, triggered by GitHub Actions. Later, Cloudflare also shared similar ideas in their engineering blog: using OpenCode to build large-scale AI code review. opencode-review aims to solve an earlier stage: within the session, before the PR, enabling the agent to proactively review and fix issues after writing code. The two complement each other: opencode-review raises the quality baseline of code entering the PR, while opencode-actions serves as the final checkpoint.
Specifically, there are three sub-problems to address:
- Incomplete review coverage: Code generated by agents may introduce security vulnerabilities and performance issues, but they won’t proactively check for these
- Lack of systematic review framework: Without structured dimensions to evaluate code, it’s easy to focus only on functional correctness while ignoring security and performance
- Lack of closed loop between issue discovery and fixes: Even when the agent discovers problems, a mechanism is needed to automatically fix them rather than waiting for someone to point them out
Design of opencode-review
Based on these three problems, I designed opencode-review: a structured code review plugin.
Multi-Dimensional Analysis
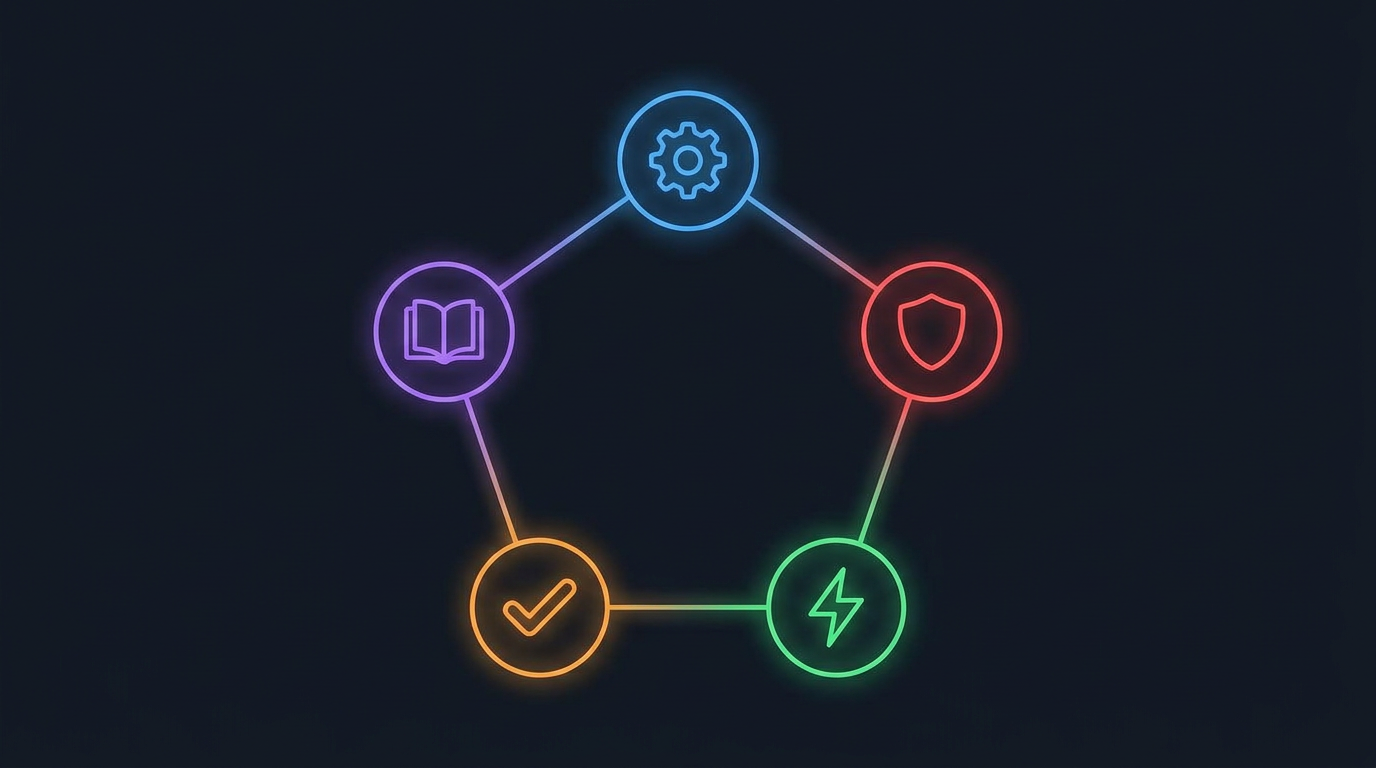
The first design decision is why divide into five dimensions rather than a general “good or bad” evaluation.
Code quality is not a single dimension. A piece of code may be functionally correct and performant, but contain SQL injection vulnerabilities; or it may be secure and harmless, but lack test coverage. Evaluating them together inevitably leads to vague results.
Academically, the Modern Code Review (MCR) Survey collected code review research from 2013-2025, proposing a classification system covering multiple task dimensions including defect detection, security review, performance analysis, and maintainability assessment. Ericsson’s research team also verified in Automated Code Review Using Large Language Models at Ericsson that dimension-specific review is more effective in industrial scenarios than general review.
opencode-review’s five dimensions—code-quality, security, performance, testing, documentation—correspond to the core review dimensions identified in these studies. Each dimension can be independently toggled because different projects focus on different priorities: an internal tool may not need documentation review, but a security-sensitive service cannot skip the security dimension.
Severity Grading
The second design decision is why divide into three severity levels (critical / suggestion / highlight).
This comes from lessons learned in the static analysis tool domain. Security tools and linters have long faced a problem: alert fatigue. When all issues are marked as equally important, developers start ignoring them. Veracode’s research points out that the direct consequence of alert fatigue is that truly serious issues get drowned out in noise.
The logic of three levels is:
- critical: Must fix (security vulnerabilities, logic errors, resource leaks)
- suggestion: Suggested improvements (code readability, performance optimization, better practices)
- highlight: Worth noting (style consistency, potential improvement space)
This way developers can prioritize handling critical issues without missing a SQL injection among a bunch of “consider refactoring” suggestions.
Auto-Fix Chain
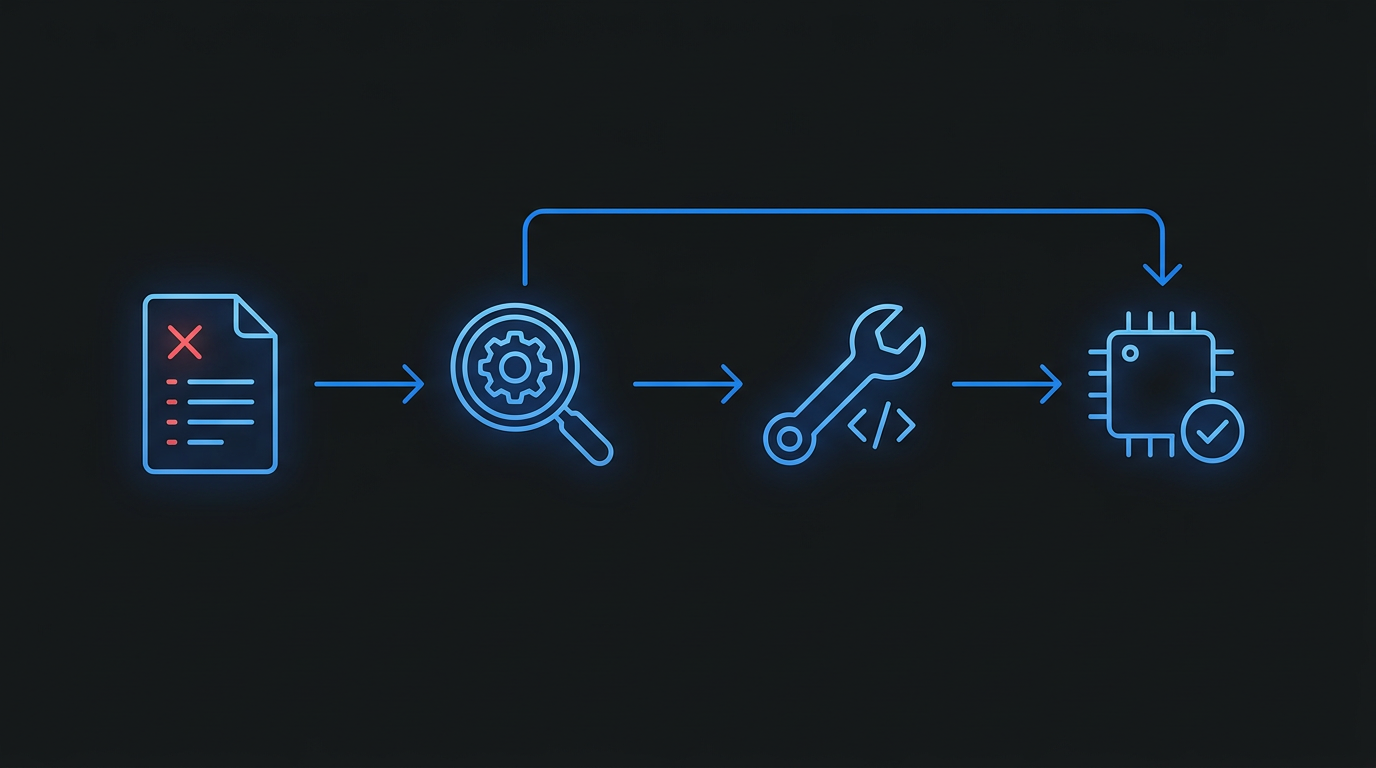
The third design decision is why critical issues should automatically trigger fixes rather than just being reported.
This is a controversial design. Traditional review tools typically “report but don’t fix,” leaving fixes to developers. But opencode-review’s scenario is different—the code it reviews is itself just written by an AI agent, so having another agent fix it is reasonable.
Academically, this belongs to the Automated Program Repair (APR) domain. A Survey of LLM-based Automated Program Repair (arXiv 2506.23749) reviewed 63 LLM-based APR systems from 2022-2025, divided into four paradigms. Among them, the “analysis-augmented” paradigm—using static analysis to locate problems first, then using LLMs to generate fixes—was proven most effective. opencode-review’s auto-fix chain is essentially this paradigm: reviewer discovers critical issue → locates problem position → spawns fixer sub-agent → generates minimal fix.
An ICSE 2025 paper also points out that a key challenge for LLMs in APR is objective alignment—the goal of fixing is not “generate code that looks reasonable,” but “precisely solve the reported problem.” This is why opencode-review’s fixer is designed as minimal fix—making only the minimal modifications to solve the problem, no rewriting, no refactoring, no “convenient” other changes.
Hidden Benefit of Auto-Review: Continuous Improvement of Code Quality Baseline
The three designs above solve “discovering problems” and “fixing problems.” But auto-review has an easily overlooked benefit: it continuously raises the baseline of code quality inadvertently.
This effect comes from two mechanisms:
First, the shaping of code writers by review feedback. FSE 2022 research found in two years of industrial practice that when developers know their code will be automatically reviewed, they consciously follow standards more during the coding phase—because the cost of being pointed out afterward becomes lower, and the benefit of writing well upfront becomes higher. This is a nudge effect. In the AI agent scenario, this effect is stronger: the agent writes code in a session, gets reviewed and pointed out issues, fixes them, gets reviewed again—this cycle can complete multiple rounds within the same session. Each round of feedback corrects the agent’s output tendency, equivalent to an implicit fine-tuning process.
Second, direct quality accumulation from automatic fixes. Critical issues being automatically fixed means the code quality of each commit is higher than without review. This isn’t a one-time improvement, but continuous. Like lint rules in a codebase—at first they only prohibit obvious errors, but as rules accumulate, the overall style and quality of the codebase is unconsciously raised. The auto-fix chain does something similar: security vulnerabilities are automatically patched, resource leaks are automatically fixed, missing tests are automatically added. Over time, the codebase’s quality baseline naturally becomes higher than without auto-review.
Simply put: review is not the goal, quality improvement is. Auto-review turns “post-hoc inspection” into “in-process improvement.”

Cooldown Mechanism
There’s one more design detail: cooldown_seconds.
auto-review triggers when the session is idle, but idle events can trigger frequently (for example, when the agent is waiting for user confirmation, it also idles). Without cooldown, the same code might be reviewed several times, wasting tokens. The default 120-second cooldown period is an empirical value—enough for one round of modifications to complete, without waiting too long.
opencode-froggy: Another Approach
opencode-froggy (85 Stars, just released 0.12.0 yesterday) provides another approach. It doesn’t do structured multi-dimensional review, but instead provides 6 specialized agents (architect, code-reviewer, code-simplifier, doc-writer, partner, rubber-duck) and a flexible hooks system.
Froggy’s code-reviewer is a general read-only review agent that doesn’t distinguish dimensions or severity. But its hooks system is strong—you can configure session.idle events to automatically run lint, auto-format, or even intercept when writing sensitive files:
| |
This is a “developer orchestrates the workflow” approach, complementing opencode-review’s “out-of-the-box structured review.”
Comparison
| opencode-review | opencode-froggy | |
|---|---|---|
| Review method | Structured multi-dimensional analysis | General code-reviewer agent |
| Severity grading | critical / suggestion / highlight | None |
| Auto-fix | critical issue → fixer sub-agent | code-simplifier, manual trigger |
| Trigger method | session idle + cooldown | hooks configuration |
| Custom rules | custom_rules supports project norms | None |
| Other features | None | 6 agents + hooks + gitingest + blockchain |
The two don’t conflict and can be installed together. My suggestion is: opencode-review for daily auto-review, froggy’s hooks for workflow orchestration.
Plugin Installation
The two plugins have different installation methods.
opencode-froggy supports direct installation via npm, just add to opencode.json:
| |
opencode-review currently doesn’t have npm installation available yet, requires cloning and local linking:
| |
opencode-review also needs to create .opencode/review.json to configure review behavior:
| |
Other Notable Plugins
The ecosystem already has over 70 plugins, here are a few more recommendations:
- opencode-worktree: Zero-friction git worktree management
- opencode-notify: Send system notifications when tasks complete
- dynamic-context-pruning: Automatically prune outdated tool outputs, optimizing token usage
- envsitter-guard: Prevent agents from reading
.envsensitive files
See the complete list at awesome-opencode.
References
- Modern Code Review (MCR) Survey — 2013-2025 code review research survey
- Automated Code Review Using LLMs at Ericsson — Industrial practice of LLM-assisted code review
- A Survey of LLM-based Automated Program Repair — LLM auto-fix survey, covering 63 systems
- Aligning the Objective of LLM-Based Program Repair (ICSE 2025) — Objective alignment issues in LLM fixing
- Understanding Automated Code Review Process (FSE 2022) — Two years of industrial environment auto-review experience
- AI-Assisted Assessment in Modern Code Review (AIware 2024) — Deployment and evaluation of AutoCommenter
- Code Review Agent Benchmark (c-CRAB) — AI agent code review benchmark
- opencode-actions - a coding review agent — GitHub Action built on OpenCode, code review at CI stage
- Cloudflare: Orchestrating AI Code Review at Scale — Cloudflare using OpenCode to build large-scale AI review