It’s not overly complex, though the preprocessing Normalize parameters are not entirely clear. It seems to use the same preprocessing parameters as ViT.
Then, moving into the model loading phase, we can see that if it’s not jit loading, the model will opt for the state_dict mode. Through the process of loading the state_dict, we can observe that the build_model function is used to load the weights and assign them to the existing model structure.
The file for this model structure is model.py. Therefore, the main code for CLIP is located at model.py#L243.
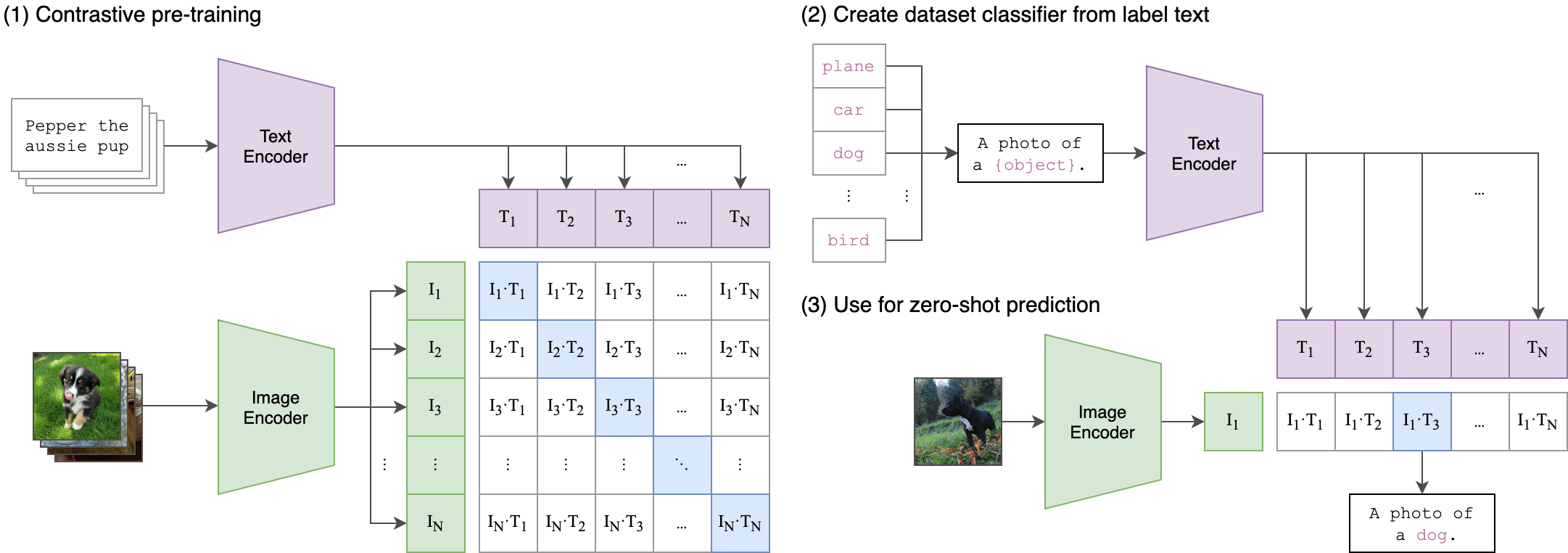
The outputs of the image_encoder and text_encoder are two distinct feature tensors.
Performing a matrix multiplication on these two tensors yields a similarity matrix. The size of this similarity matrix is (batch_size, batch_size).
TIPS: If the batch size is too small, such as 1, the performance of contrastive learning may be significantly diminished.
These two tensors are computed using symmetric cross-entropy loss to update the network weights.
Specifically focused on improving intelligence metrics, without much concern for computational cost. Not pursuing the latest or highest intelligence metrics, but more focused on the computational efficiency of the model.
Trick: Adding a log to the parameters to make weight updates less drastic and reduce computational intensity.
The CLIP code does not provide directly trainable code. In the next article, we’ll attempt to read openclip.