最近一年里,我尝试使用 deepchat 和 大模型 API(例如 k2 thinking turbo) 来构成一个相对私有化的聊天工具(或者说 agent 助手),来处理一些私有化的数据。但是,总的来说体验不是很好。大模型答不对。
搜索方面,我使用了 bocha api,重置了 10 块,来为大模型提供搜索能力。
测试的问题
我感觉上下文能力(单一聊天框内)还是有点问题。我简单测试了这个问题:硅基流动上,最贵的模型是哪一个?。
答案是:
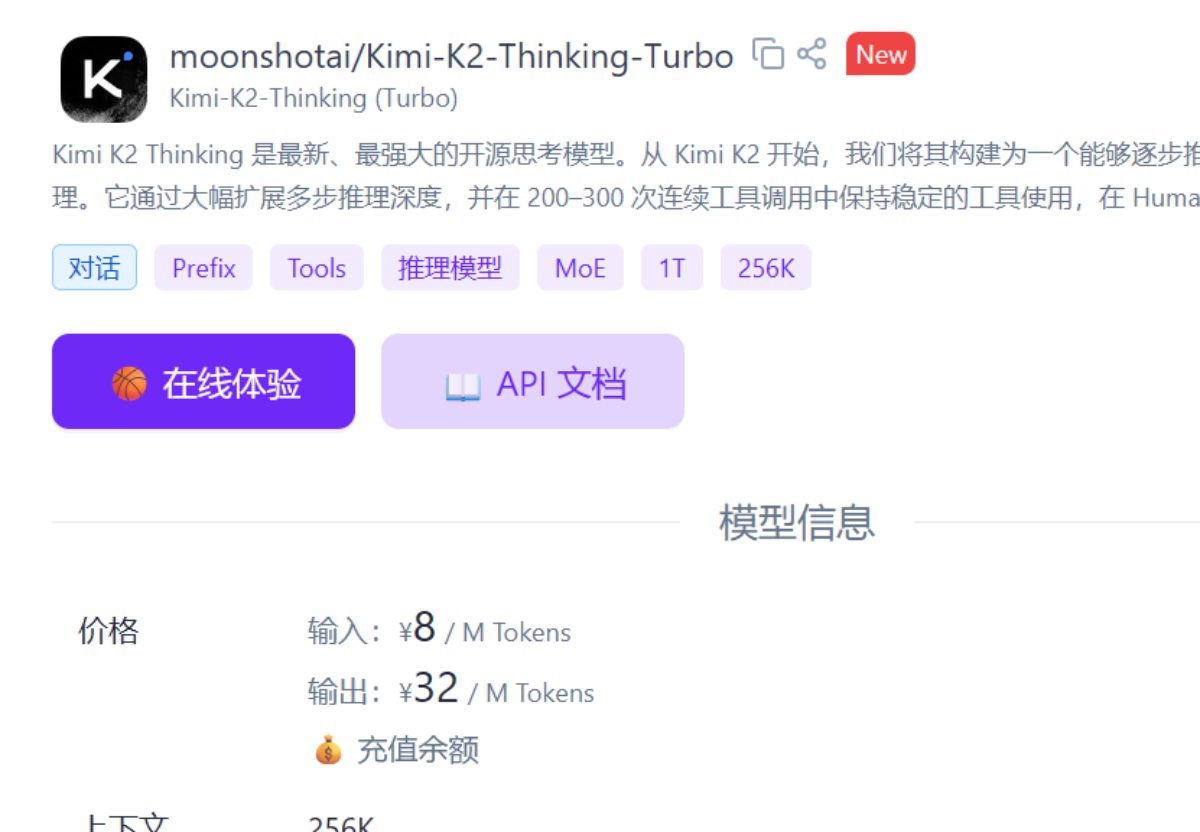
Kimi k2 thinking turbo
首先是 deepchat:
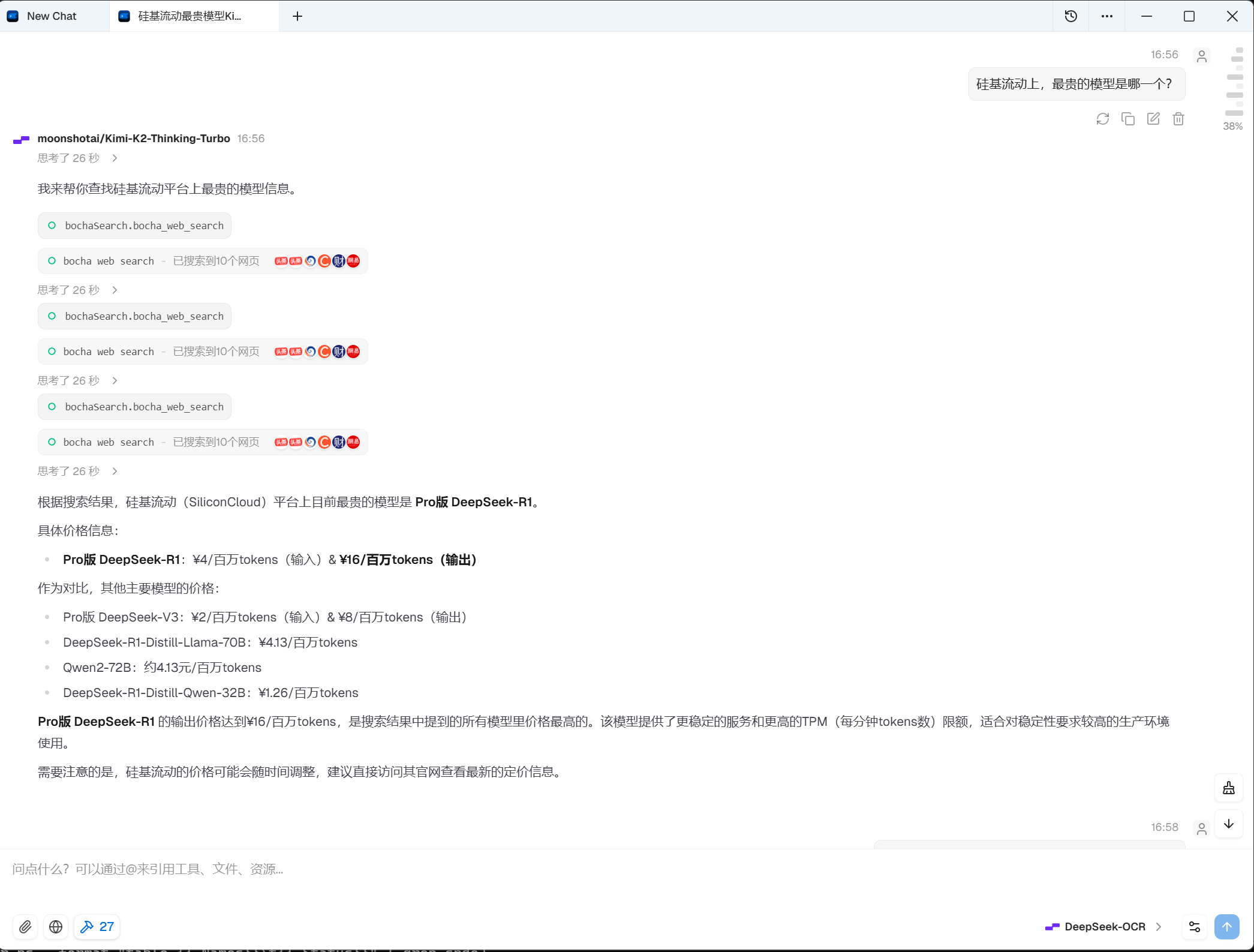
emm,不对。
然后是 kimi official:

也不对。
试试 deepseek
先试试客户端。

不对。
再试试 deepseek official。

很接近,答案也靠谱了。但是可惜,也不对。
如果直接问 chatgpt
嘶,有点离谱。让我们试试 gpt-5。
prompt:
| |

推断-性能不好的原因
- 搜索能力不足。博查 API 背锅。
- 不同模型,最佳表现的超参数可能不一样。我调用的是硅基流动的大模型 API。
结论
- 单从这个问题上看,还是 chatgpt 强一些。相比之前,官方的搜索+模型,似乎性能也会更好一些。因此,如果不是特别隐私的数据,还是用官方的比较好。
- 本文仅供参考,看个乐子。