
语速
上下文压缩是 coding agent 必备的特性。
最近翻 Codex 文档,看到一个点:它明确提到了 server-side compaction。
我觉得这个点挺有意思。不是说"压缩上下文"这件事本身有多新鲜,而是它把这件事放在服务端做,并且写进了文档。也就是说,上下文管理不是用户自己在提示词层面想办法,而是产品本身就内建了一套机制。
顺手我又去看了一下 OpenCode 的 compaction。两边都叫 compaction,但不是一回事。
Codex 这边强调的是:服务端在上下文达到阈值时,会把前面的交互压缩成一个更短的表示,后续请求继续带着这个压缩后的状态跑。文档里写得很清楚,server-side compaction 会用更少的 tokens 携带之前的关键状态。

OpenCode 这边,我看了一下源码,它也有 compaction,但更像应用层的会话压缩:上下文快满时,调用一个隐藏的 compaction agent 生成 summary,后续请求不再带完整旧历史,而是保留这段 summary 继续。还有 prune 会把旧的工具输出清掉,只保留占位文本。
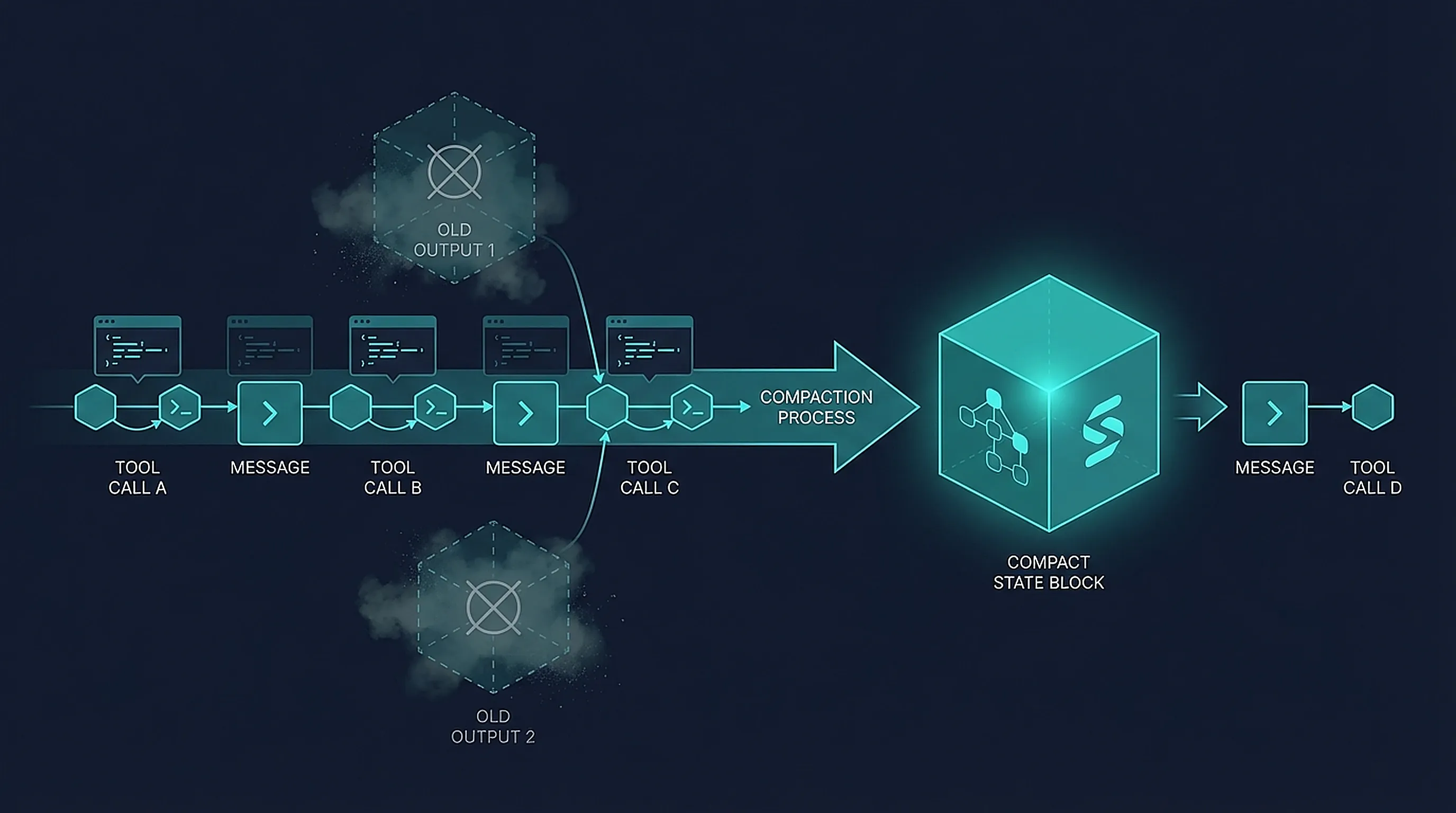
所以两边虽然名字一样,但关注点不一样:
- Codex:服务端的上下文管理能力
- OpenCode:应用层的会话状态续写
这个区分我觉得值得记一下。很多人看到同一个词,就默认是同一种机制,其实不是。与其急着比较谁更省、谁更好,不如先把机制边界看清楚。