
之前我写过一篇 OpenCode 配置优化记录,解决的是 token 消耗和上下文管理的问题。但配置优化管的是"模型怎么跑",而"代码写到一半质量怎么样"——这件事配置管不了。这篇文章从我开发 opencode-review 插件的过程出发,聊聊 opencode-review 如何在一个 session 内帮助 agent 审查并改进自己的代码,让最终进入 PR 的代码质量更高。
问题:session 内的代码质量谁来把关?
用 OpenCode 写代码时,一个典型的工作流是:agent 在一个 session 内完成编码,然后我 review diff、创建 PR。但我发现一个反复出现的问题:agent 写完的代码经常带着"第一次草稿"的质量问题就进入 PR 了。
这些问题包括:缺少错误处理、安全漏洞、性能不佳的查询、缺失的测试。如果能在 session 内——也就是代码还没提交到 PR 之前——让 agent 自行审查一轮,很多问题在 PR 阶段就不存在了。
这和 CI 阶段的 code review 是不同层次的事情。CI 审查我已经通过 opencode-actions(之前写过一篇介绍文章)实现了——它发生在 PR 创建之后,由 GitHub Actions 触发。后来 Cloudflare 也在工程博客中分享了类似思路:用 OpenCode 构建大规模 AI code review。而 opencode-review 要解决的是更早的阶段:在 session 内、在 PR 之前,让 agent 在写完代码后主动审查并修复问题。两者互补:opencode-review 提升进入 PR 的代码质量基线,opencode-actions 则作为最后一道关卡。
具体来说,有三个需要解决的子问题:
- 审查覆盖不全:agent 生成的代码可能引入安全漏洞、性能问题,但它自己不会主动检查这些
- 缺乏系统性的审查框架:没有结构化的维度来评估代码,容易只关注功能正确性而忽略安全和性能
- 发现问题和修复之间缺乏闭环:即使 agent 发现了问题,也需要一个机制来自动修复,而不是等人来指出
opencode-review 的设计
基于这三个问题,我设计了 opencode-review:一个结构化的代码审查插件。
多维度分析
第一个设计决策是为什么分五个维度,而不是一个笼统的"好不好"的评价。
代码质量不是一个单一维度。一段代码可能功能正确、性能优秀,但存在 SQL 注入漏洞;也可能安全无害,但缺少测试覆盖。把它们混在一起评估,结果必然模糊。
学术上,Modern Code Review (MCR) Survey 收集了 2013-2025 年间的代码审查研究,提出了一个分类体系,涵盖缺陷检测、安全审查、性能分析、可维护性评估等多个任务维度。Ericsson 的研究团队在 Automated Code Review Using Large Language Models at Ericsson 中也验证了:按维度拆分的审查比笼统审查在工业场景中更有效。
opencode-review 的五个维度——code-quality、security、performance、testing、documentation——对应的就是这些研究中识别出的核心审查维度。每个维度可以独立开关,因为不同项目关注的重点不同:一个内部工具可能不需要文档审查,但一个安全敏感的服务不能跳过 security 维度。
严重性分级
第二个设计决策是为什么分三级严重性(critical / suggestion / highlight)。
这来自静态分析工具领域的经验教训。安全工具和 linter 长期面临一个问题:alert fatigue(告警疲劳)。当所有问题都被标记为同等重要时,开发者会开始忽略它们。Veracode 的研究指出,告警疲劳导致的直接后果是真正的严重问题被淹没在噪音中。
分三级的逻辑是:
- critical:必须修复(安全漏洞、逻辑错误、资源泄漏)
- suggestion:建议改进(代码可读性、性能优化、更好的实践)
- highlight:值得注意(风格一致性、潜在的改进空间)
这样开发者可以优先处理 critical,而不会在一堆 “consider refactoring” 中错过一个 SQL 注入。
自动修复链
第三个设计决策是为什么 critical 问题要自动触发修复,而不是仅仅报告。
这是一个有争议的设计。传统的审查工具通常是"只报告不修复",把修复留给开发者。但 opencode-review 的场景不同——它审查的代码本身就是 AI agent 刚写完的,让另一个 agent 去修复合情合理。
学术上这属于 Automated Program Repair (APR) 的范畴。A Survey of LLM-based Automated Program Repair (arXiv 2506.23749) 综述了 2022-2025 年间的 63 个 LLM-based APR 系统,分为四种范式。其中"分析增强"(analysis-augmented)范式——先用静态分析定位问题,再用 LLM 生成修复——被证明是最有效的。opencode-review 的 auto-fix chain 本质上就是这个范式:reviewer 发现 critical issue → 定位问题位置 → spawn fixer sub-agent → 生成最小化修复。
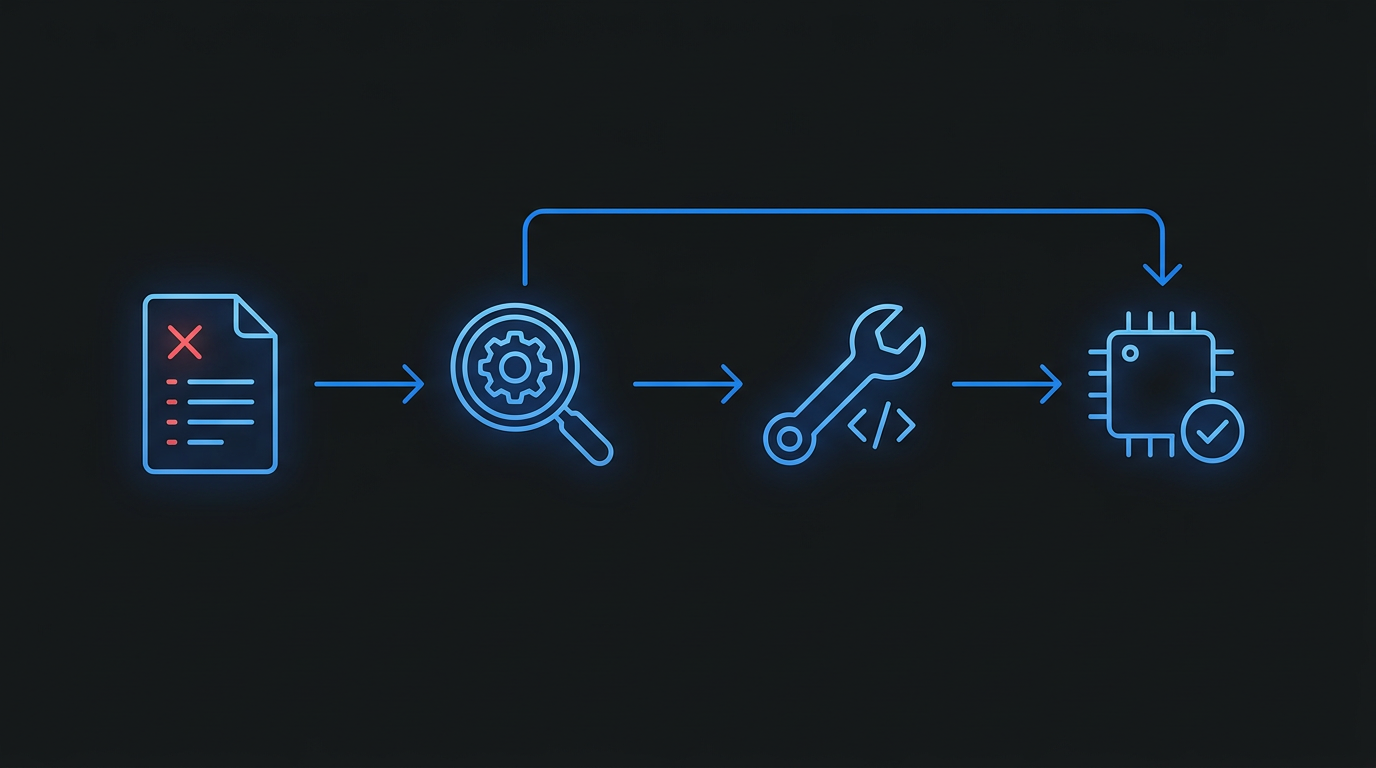
ICSE 2025 的一篇论文 也指出,LLM 在 APR 中的关键挑战是目标对齐(objective alignment)——修复的目标不是"生成看起来合理的代码",而是"精确解决报告的问题"。这也是为什么 opencode-review 的 fixer 被设计为 minimal fix——只做最小的修改来解决问题,不重写、不重构、不"顺手"做其他改动。
自动审查的隐性收益:代码质量基线的持续提升
上面三个设计解决的是"发现问题"和"修复问题"。但自动审查还有一个容易被忽略的好处:它在不经意间持续提升了代码质量的基线。
这个效果来自两个机制:
第一,审查反馈对写代码者的塑造。 FSE 2022 的研究 在两年的工业实践中发现,当开发者知道自己的代码会被自动审查时,他们会在写代码阶段就更有意识地遵循规范——因为事后被指出来的成本变低了,提前写好的收益变高了。这是一种 nudge effect(助推效应)。在 AI agent 的场景下,这个效应更强:agent 在一个 session 中写了代码、被 review 指出问题、修复、再次被审查——这个循环在同一 session 内就能完成多轮。每一轮反馈都在修正 agent 的输出倾向,相当于一个隐式的 fine-tuning 过程。
第二,自动修复的直接质量累积。 critical issue 被自动修复意味着每一轮提交的代码质量都比没有审查时更高。这不是一次性的改进,而是持续的。就像代码库中的 lint 规则一样——一开始只是禁止明显错误,但随着规则积累,代码库的整体风格和质量在不知不觉中被拉高了。auto-fix chain 做的事情类似:安全漏洞被自动堵上、资源泄漏被自动修复、缺失的测试被自动补充。时间一长,代码库的质量基线自然高于没有自动审查的情况。
简单说:审查不是目的,质量提升才是。自动审查把"事后检查"变成了"过程中提升"。

Cooldown 机制
还有一个小的设计细节:cooldown_seconds。
auto-review 在 session idle 时触发,但 idle 事件可能频繁触发(比如 agent 在等待用户确认时也会 idle)。没有 cooldown 的话,同一份代码可能被审查好几次,浪费 token。120 秒的默认冷却期是一个经验值——足够让一轮修改完成,又不会等太久。
opencode-froggy:另一种思路
opencode-froggy(85 Stars,昨天刚发 0.12.0)提供了另一种思路。它不做结构化的多维度审查,而是提供 6 个专用 agent(architect、code-reviewer、code-simplifier、doc-writer、partner、rubber-duck)和一套灵活的 hooks 系统。
Froggy 的 code-reviewer 是一个通用的只读审查 agent,不区分维度和严重性。但它的 hooks 系统很强——你可以配置 session.idle 事件自动跑 lint、自动格式化、甚至在写入敏感文件时拦截:
| |
这是一种"开发者自己编排流程"的思路,和 opencode-review 的"开箱即用的结构化审查"形成互补。
对比
| opencode-review | opencode-froggy | |
|---|---|---|
| 审查方式 | 结构化多维度分析 | 通用 code-reviewer agent |
| 严重性分级 | critical / suggestion / highlight | 无 |
| 自动修复 | critical issue → fixer sub-agent | code-simplifier,需手动触发 |
| 触发方式 | session idle + cooldown | hooks 配置 |
| 自定义规则 | custom_rules 支持项目规范 | 无 |
| 其他功能 | 无 | 6 agent + hooks + gitingest + 区块链 |
两个不冲突,可以一起装。我的建议是:opencode-review 做日常自动审查,froggy 的 hooks 做流程编排。
插件安装
两个插件的安装方式不同。
opencode-froggy 支持通过 npm 直接安装,在 opencode.json 中添加即可:
| |
opencode-review 目前 npm 安装尚未上线,需要 clone 后本地链接:
| |
opencode-review 还需要创建 .opencode/review.json 来配置审查行为:
| |
其他值得关注的插件
生态已经超过 70 个插件了,再推荐几个:
- opencode-worktree:零摩擦的 git worktree 管理
- opencode-notify:任务完成时发送系统通知
- dynamic-context-pruning:自动裁剪过时的工具输出,优化 token 使用
- envsitter-guard:阻止 agent 读取
.env敏感文件
完整列表见 awesome-opencode。
参考文献
- Modern Code Review (MCR) Survey — 2013-2025 代码审查研究综述
- Automated Code Review Using LLMs at Ericsson — LLM 辅助代码审查的工业实践
- A Survey of LLM-based Automated Program Repair — LLM 自动修复综述,覆盖 63 个系统
- Aligning the Objective of LLM-Based Program Repair (ICSE 2025) — LLM 修复的目标对齐问题
- Understanding Automated Code Review Process (FSE 2022) — 两年工业环境自动审查的经验总结
- AI-Assisted Assessment in Modern Code Review (AIware 2024) — AutoCommenter 的部署与评估
- Code Review Agent Benchmark (c-CRAB) — AI agent 代码审查基准测试
- opencode-actions - 一个 coding review agent — 基于 OpenCode 构建的 GitHub Action,CI 阶段的 code review
- Cloudflare: Orchestrating AI Code Review at Scale — Cloudflare 用 OpenCode 构建大规模 AI 审查