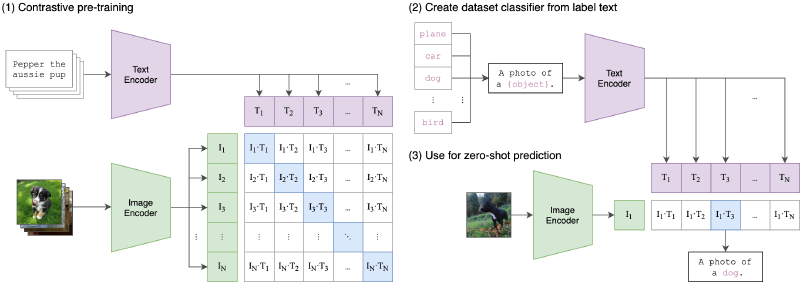
Contrastive Language-Image Pre-Training (CLIP) 是 openai 的经典工作之一。出自论文
为了能够在 CLIP 上完成我的新 idea,我尝试阅读 openai/clip 来理解 clip 在 classifier 上的基本工作原理。
这是 openai/clip 给出的 python 样例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
|
load 函数用于加载特定的 openai 模型。这里是基于ViT-B/32,一个 Vision Transformer 32B。
可以看到,如果 openai 支持的 vision encoder 大概有如下几种:
1
2
3
4
5
6
7
8
9
10
11
| _MODELS = {
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
"ViT-L/14@336px": "https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
}
|
我们假设模型已经下载完成,让我们看看 _tranform 预处理工作是如何进行的:
1
2
3
4
5
6
7
8
| def _transform(n_px):
return Compose([
Resize(n_px, interpolation=BICUBIC),
CenterCrop(n_px),
_convert_image_to_rgb,
ToTensor(),
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
|
也不是很复杂,预处理Normalize参数虽然不太明白。似乎是用的 ViT 同样的预处理参数。
然后进入模型加载阶段,我们可以看到,如果不是 jit 加载 ,那么模型会选择 state_dict 的模式。
通过加载 state_dict 的过程,我们可以看到 build_model 函数用于加载权重,将权重赋值给已有的模型结构。
这个模型结构的文件是model.py。
因此,CLIP 的主要代码位于model.py#L243。
image_encoder 和 text_encoder 的输出,分别是两个不同的特征 tensor。
将两个 tensor 进行矩阵乘积,分别得到一个相似性矩阵。这个相似性矩阵的大小是 (batch_size, batch_size)。
TIPS: 如果说 batch-size 太小,为1,那么对比学习的性能可能就大打折扣了。
这两个 tensor 使用 symmetric cross-entropy loss 进行计算,来用于更新网络权重。
专门做智能指标的提升,不太在意计算量。不追求最新最高的智能指标,更加关注模型计算的运行效率。
trick: 给参数加一个 log 来使得权重更新没有那么剧烈,计算起来没有那么大。
CLIP 代码中没有给出能够直接进行训练的代码。下一篇文章,尝试阅读一下 openclip。